服务热线:
发布时间: 2024-09-23 06:07:35 来源:产品中心
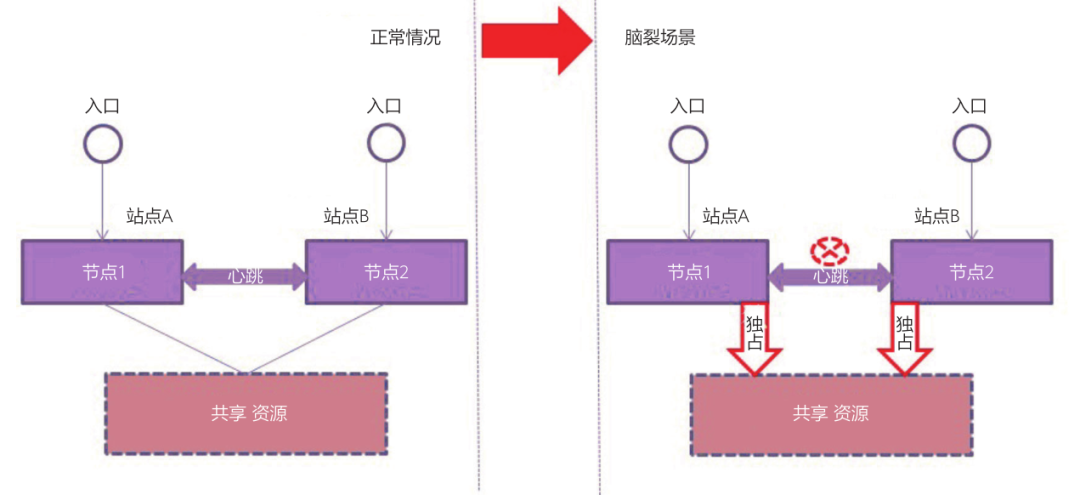
在容灾架构设计当中,我们大家常常会利用一些HA、Cluster等高可用架构在其中,而且一般都是借助于跨地域L2网络,采用跨数据中心的方式在某一个功能层组成一个独立的集群,例如数据库集群、存储网关集群等。假设因为两个数据中心节点通讯中断故障导致形成了两个独立的集群,彼此独立工作,那么这就是脑裂。正如图1所示情况。

现实环境当中,导致集群有几率发生脑裂最典型的场景就是网络的面积性故障。例如所有集群节点相互之间的通讯网络中断;导致双活数据中心之间有几率发生脑裂的场景就是双数据中心之间的光纤线路中断。所以在容灾设计当中,脑裂问题是架构师必须要考虑的关键性问题。通常来讲成熟的数据库集群和存储集群都会有自己应对脑裂问题的机制,通常有优先级策略和仲裁策略两种。
这个问题是需要回到集群的仲裁机制上来。通常来说,集群的仲裁算法是以每一个节点能够得到仲裁资源的多少来判断谁是集群的主导。集群的仲裁资源无非是来自互联网层面的心跳信息和共享存储的磁盘心跳资源,在普通的节点层故障场合下,出现故障的节点能够得到的仲裁资源就会少于其他节点,那么就不会发生脑裂问题。但是在一种特殊的场合(双数据中心之间的网络发生了故障),两个节点能够得到的仲裁资源是一样的,网络彼此不能互通,存储彼此不能看到对方,这样的场景下仲裁就会失效,脑裂发生。
那么为啥说对于容灾架构来讲,脑裂是灾难性的事件呢?如果从一个统一集群的调度变成两个相互独立的集群调度,意味着双方的写操作相互也是独立的,但是他们的存储空间是共享的,AA模式下通过锁机制控制并发,HA模式下通过存储卷的Owner控制写的权限。但是独立之后意味着两个集群可以每时每刻写入同样的存储地址,必然会导致脏写脏读等一系列数据不一致,这对业务来讲是灾难性的。曾经有一家金融企业的HA集群因为集群仲裁触发的时间参数与交换机上的链路切换时间参数不协调而导致了脑裂问题的发生,花费了大量人力财力进行业务及数据恢复,最终仍丢失了若干小时的数据。
所以,这类问题对公司的业务数据是个巨大的风险,在容灾设计当中是必考虑之关键问题。
赵海主编:在前面重要概念取得共识后,本议题将由利安人寿资深工程师陈萍春、哈尔滨银行系统专家团队存储管理员张鹏分别主张议题下的相关关键点,几位专家的主张在某金融科技公司高级技术主管张鹏及我本人的复议下,各位专家的主张最终形成一定的共识供同行参考。
需要根据脑裂场景严格区别和正确认知三种脑裂:心跳链路中断引起的脑裂,心跳链路抖动引起的脑裂、仲裁结果不一致引起的脑裂。
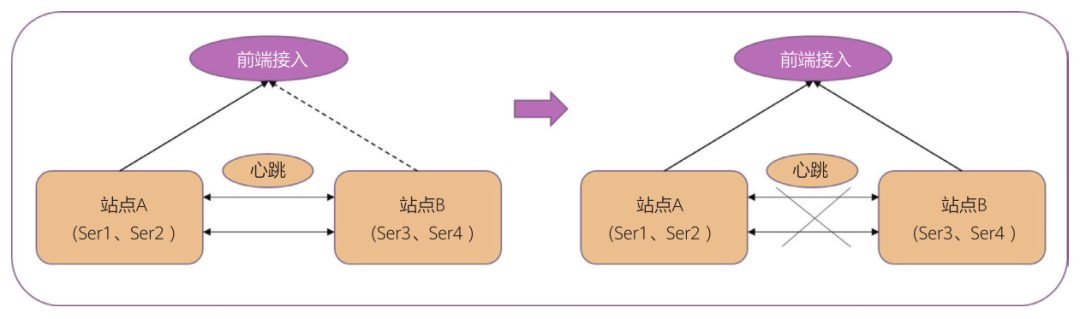
假设节点1和节点2组成跨站点的集群架构,每个站点都提供了集群入口,节点之间通过心跳连接,并协调访问共享资源。心跳主要能用于节点间互相检查对方的存活状态,并能协调访问共享资源。而共享资源最重要的包含存储、网络以及应用服务等,大多数情况下是一定要通过集群的锁机制来保证一致性的。
心跳链路中断故障可能是网络线路中断造成,也可能是心跳链路端点的网络设备故障造成的。如图2所示,若发生心跳链路中断的故障,节点1发出的心跳检测信号长时间得不到确认,就会判断节点2不活,从而接管共享资源;而节点2也会做出节点1不活的判断,从而接管共享资源,形成脑裂。资源的共享模式一旦转为独占模式,有极大几率会出现两个节点同时对外提供原来由集群协调的应用服务和网络,造成应用层、网络层的冲突;还可能会出现关键数据被同时访问及存储层的访问冲突情况,这就会破坏了数据的一致性,甚至会造成数据损坏的情况。
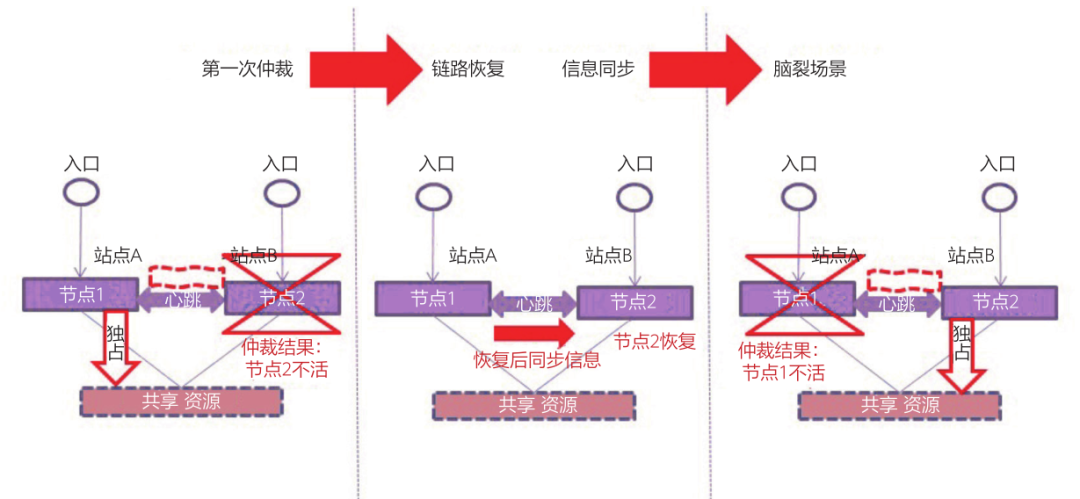
心跳链路抖动故障的产生一般是由于站点间的光纤质量上的问题导致链路不稳定的状态。如图3所示,心跳链路抖动故障可能会持续触发集群仲裁,过程假设如下:链路质量不稳定,触发第一次仲裁时,判定节点1存活,节点2不活;链路恢复,触发第二次仲裁,判定节点2恢复,节点1会发起向节点2的信息同步过程;信息同步过程中,链路又出现故障,触发第三次仲裁,这次如果判断节点2存活,节点1不活,节点2会接管资源。由于信息未完成同步,节点1和节点2的数据一致性无法保证,形成了脑裂。
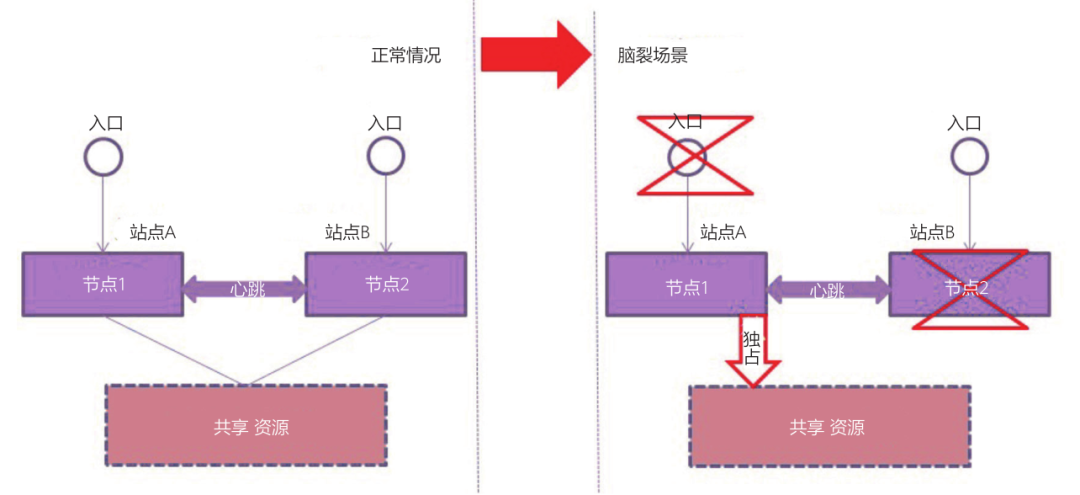
如果节点的入口和共享资源是分开的,故障的仲裁结果出现不一致的情况,也会形成脑裂。如图4所示,节点入口发生故障,仲裁结果是节点1的入口不活;同时节点的共享资源也发生故障,仲裁结果是节点1独占共享资源。这时候节点1可以访问共享资源,但没有入口;节点2有入口,但没有共享资源,这也形成了脑裂。
要解决脑裂问题,第一步是要正确理解脑裂的形成,导致的原因,脑裂的后果以及常见的几种解决方案。
脑裂的概念最早在主机的集群中普遍的使用,在容灾双活系统中概念依然延续使用可以类比。假设有同一个整体、动作协调的节点A(站点A) 和节点B(站点B),A和B之间通过心跳来检查对方的存活状态,负责协调保证总系统服务的可用性。一般的情况下,如果节点A通过心跳检测不到B存在的时候,就会接管B的资源,同理节点B检查不到A的存活状态时候也会接管A的资源。假如慢慢的出现网络故障,两个节点的“心跳线”断开,本来为一个整体、数据同步、动作协调的系统,就分裂成为两个独立的节点A和节点B系统,相互之间失去了联系,都以为是对方出了故障,两个节点上的应用软件像“裂脑人”一样,“本能”地争抢“共享资源”、争起“应用服务”,造成:1)共享资源被瓜分、两边“服务”都起不来了;2)或者两边“服务”都起来了,但同时读写“共享存储”,导致数据损坏,这样的一种情况被称为脑裂现象。因此,站点A和站点B在某项功能层组成了一个独立的集群,即一个“大脑”,由于某些原因,站点A和B的心跳中断,形成了两独立的集群,即两个“大脑”,而当一个人有两个大脑,并相互独立时,那么必然会出问题,造成系统宕机,正如一个人不能在向前走的同时接受另一个大脑向后走的指令一样。
当容灾系统中出现脑裂现象时,第一先考虑心跳线路上的问题,其次是心跳服务。软件层面的问题,主要有以下几点原因:
4)其他服务配置不当等原因,如心跳的方法不一样,心跳广播冲突,软件出现了BUG等。
在容灾系统中,当发生脑裂现象时,会造成以下两种问题,对业务和数据造成影响。
1)引起数据的不完整性:集群中节点(在脑裂期间)同时访问同一共享资源,而且没有机制去协调控制的话,那么就存在数据不完整性的可能。
针对容灾系统中的脑裂问题,通常是以心跳检测为依据来防止脑裂,有如下几种方案:
1)同时使用串行电缆和以太网电缆连接,同时用两条心跳线路,这样一条线路坏了,另一个线路还是好的,依然能传送消息。
2)检测到裂脑的时候强行的关闭一个心跳节点,相当于程序上备节点发现心跳线故障,发送关机命令到主节点。
a. 增加一个仲裁机制。例如设置参考的IP,当心跳完全断开的时候,2个节点各自都ping一下参考的IP,不通则表明断点就出现在本段,这样就主动放弃竞争,让能够ping通参考IP的一端去接管服务。
4)启用磁盘锁。正在服务一方锁住共享磁盘,脑裂发生的时候,让对方完全抢不走共享的磁盘资源。但使用锁磁盘也会有一个不小的问题,如果占用共享盘的乙方不主动解锁,另一方就永远得不到共享磁盘。现实中介入服务节点突然死机或者崩溃,另一方就永远不可能执行解锁命令。后备节点也就接手不了共享的资源和应用服务。于是有人在HA中设计了“智能”锁,正在服务的一方只在发现心跳线全部断开时才启用磁盘锁。
“三活”数据中心这个概念出自阿里巴巴,这是首个实现多活(2个以上)的大型数据中心,意义非凡。虽然我们在各种技术文章中常常看到讨论多活技术,但是实际上都是理论研究,从未经过实践。所谓多活,一是多中心之间地位均等,正常模式下协同工作,并行的为业务访问提供服务,实现了对资源的充分的利用,避免一个或两个备份中心处于闲置状态,造成资源与投资浪...
在医院发展中,信息化建设为医院各项工作提供系统性、基础性和服务性支撑,并且促使医院文化内涵发生改变,但是随着医院信息系统的快速发展和业务大集中速度的加快,也出现了一系列问题:虚拟化、集群、分布式技术、移动办公的广泛应用,让业务系统的可靠性面临严峻挑战。针对用户业务系统重要性的不同,只用一种备份产品是不是能适应未来发展怎么来面对未来呈...
武汉大学中南医院座落于风光旖旎的东湖之滨,毗邻武汉中央文化区“楚河汉街”。医院先后被国家卫生部授予首批三级甲等医院、全国百佳医院、爱婴医院、全国卫生系统先进集体、全国援外医疗工作先进集体等称号。是湖北省文明单位、武汉地区文明品牌医院。为武汉市城镇职工、居民医保定点医院、AAA级新农合省级定点医疗机构。[[174621]]中南医院信息化建设需...

